
DSM-5(精神疾患の分類と診断の手引き)の診断基準の一部を、あえてAIのニューラルネットワークで表現してみようと思います。心理臨床家のための、DSM-5を使った人工知能入門でもあります。
なんだか大袈裟なタイトルになってしまいましたが、目的は次のとおりです。
- 心理臨床家が昨今のAIがどのような性質のものであるかを知るヒント。
- AIが臨床の未来に与える影響について視野を広げる示唆。
- 人間以外の視点から振り返ることで、これまでの臨床がどのようなものであるか考えるきっかけ。
なお、話はとっても単純化しています。
ここでは診断基準はアセスメントの例として挙げており、診断基準やDSM-5を説明する記事ではありません。
※診断は医療行為ですので、心理セラピストが診断基準を使って診断をすることはありません。
ニューラルネットワークの説明
脳細胞(ニューロン)をモデルに、次のような仮想的な機械部品を想定します。ここでは専門用語を増やさないために、この部品を思い切って「ニューロン」と呼んでしまうことにします。
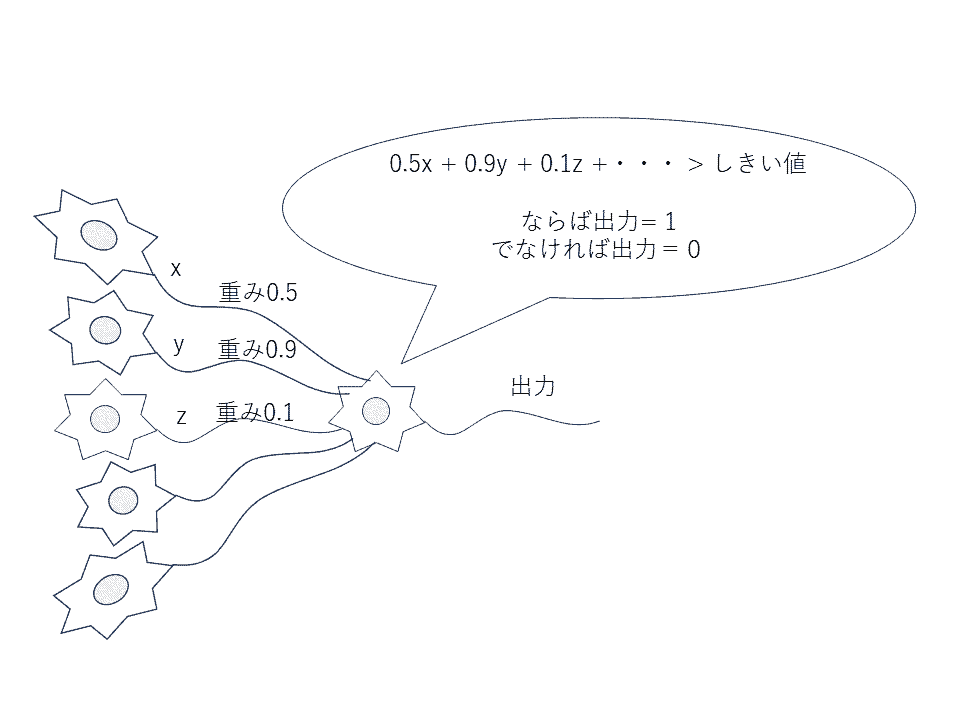
ニューロンは軸索(神経線維、図中の線状の部分)を通して信号を出力します。ひとまずは、0または1を出力するものとします。軸索の先は枝分かれして複数の後ニューロンに接続しますが、それらの出力内容は1つです。
出力の決め方は、他のニューロンから受け取る信号を多数決のように加算して、閾値(しきいち)と比べます。「友達から賛成意見をたくさん聞いたら、自分も賛成する」みたいな感じです。ただし、どのニューロンからの信号を重くみるか、あるいは軽く見るか、無視するかが決まっていて、それを「重み」といいます。
上図の例ではyからの信号を重く扱い、zからの信号を軽く扱っています。
ニューロン1個の数理
以上を数式で表現すると次のようになります。
\[ニューロンの出力 = step(\sum (他のニューロンの出力 × 重み) - 閾値 )\]※Σは総和の記号です。
\[\sum x = x_1 + x_2 + x_3 \dots + x_n\]
※stepは負に対して0を、正に対して1を返すステップ関数です。
\[step(x) = \begin{cases} 0 \text{ if } x \lt 0 \cr 1 \text{ if } x \geq 0 \end{cases}\]
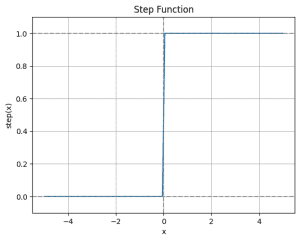
数式が苦手であったとしても、次のことは理解してください。
数式で表現できるということは、コンピュータに真似させることが出来るということを意味します。
運がよければ解析という魔法も使えます。
うつ病診断のニューラルなモデル
うつ病(大うつ)の診断基準(の一部を簡略化したもの)をニューラルネットワークを用いて描いてみます。
※実際の診断基準よりも簡略化しています。
※診断する人間の実際の脳細胞とは異なります。しかし、原理は似ているかもしれません。
うつ病の診断は、9組の症状のうち5つ以上該当することが基準となっていますが、「抑うつ気分」または「喜びの減退」が必須になっています。
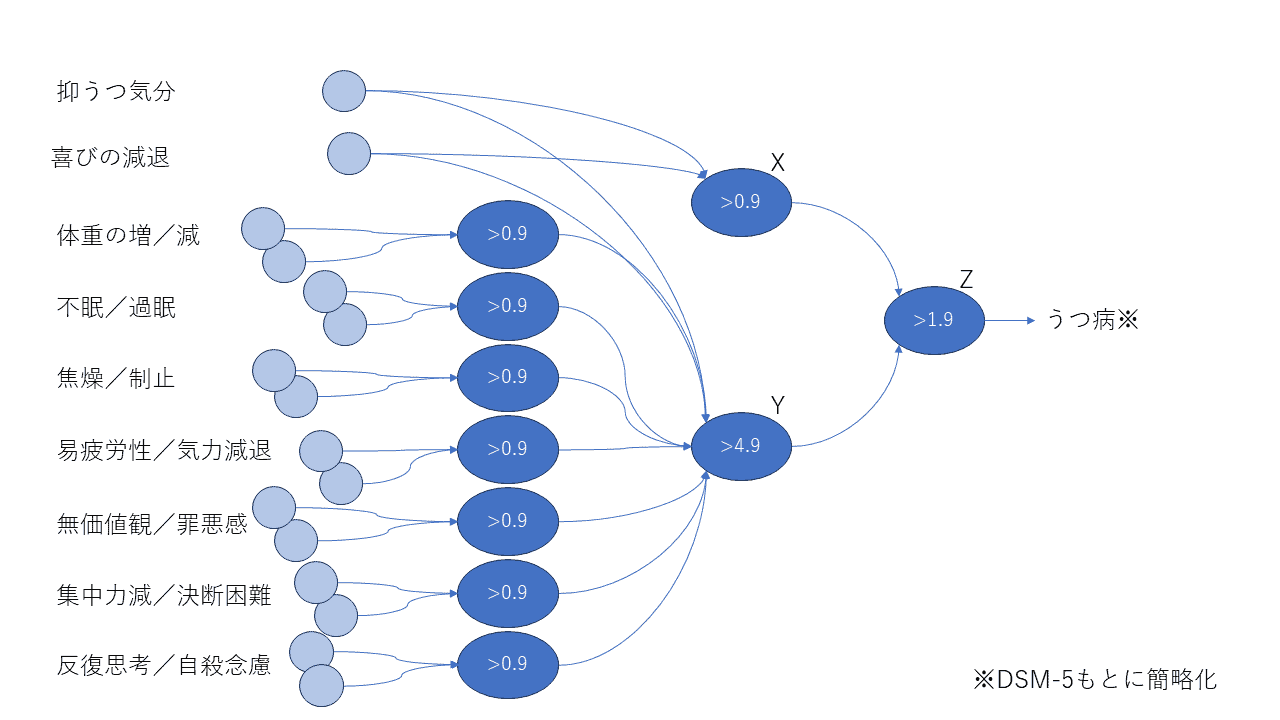
重みは0か1です。(図で接続線が繋がっていれば1)
患者に該当する症状があれば入力層の該当ニューロン(図中左の水色丸)が反応します。
たとえば、「抑うつ気分」と「喜びの減退」のどちらもなければ、図中のニューロンXは0と0を受信した結果、
0+0 < 0.9
となるので、Xは反応しません。
「抑うつ気分」のみあれば、1と0を受信して、
1+0 > 0.9
となり、Xは反応します。「どちらか1つでもあれば」を表しています。
まとめると、次の表のとおりです。
| 抑うつ気分 | 喜びの減退 | ニューロンX | |
|---|---|---|---|
| 1 | 1 | 1+1 > 0.9 | 1 |
| 1 | 0 | 1+0 > 0.9 | 1 |
| 0 | 1 | 0+1 > 0.9 | 1 |
| 0 | 0 | 0+0 < 0.9 | 0 |
一方で、図中のニューロンZは、閾値が1.9なので少し違います。2つのニューロンXとYの両方が反応したときのみ、ニューロンZは反応します。
1+1 > 1.9
0+0や1+0や0+1では反応しません。「両方あれば」を表しています。
| ニューロンX | ニューロンY | → | ニューロンZ |
|---|---|---|---|
| 1 | 1 | 1 + 1 > 1.9 | 1 |
| 1 | 0 | 1 + 0 < 1.9 | 0 |
| 0 | 1 | 0 + 1 < 1.9 | 0 |
| 0 | 0 | 0 + 0 < 1.9 | 0 |
どうやら、閾値の低いニューロン(たとえばX)は十分条件を探していて、閾値の高いニューロン(たとえばZ)は必要条件の情報を集めているようですね。
ニューロンXが「『抑うつ気分』または『喜びの減退』」を判定し、ニューロンYが「9組の症状のうち5つ以上該当する」を判定しています。そして、ニューロンZはそれら両方が成立していることを判定しています。
次の例も見てみましょう。
PTSD診断のニューラルなモデル
もう少し簡単な例として、PTSDの診断基準(の一部を簡略化したもの)を見てみましょう。
※実際の診断基準よりも簡略化しています。
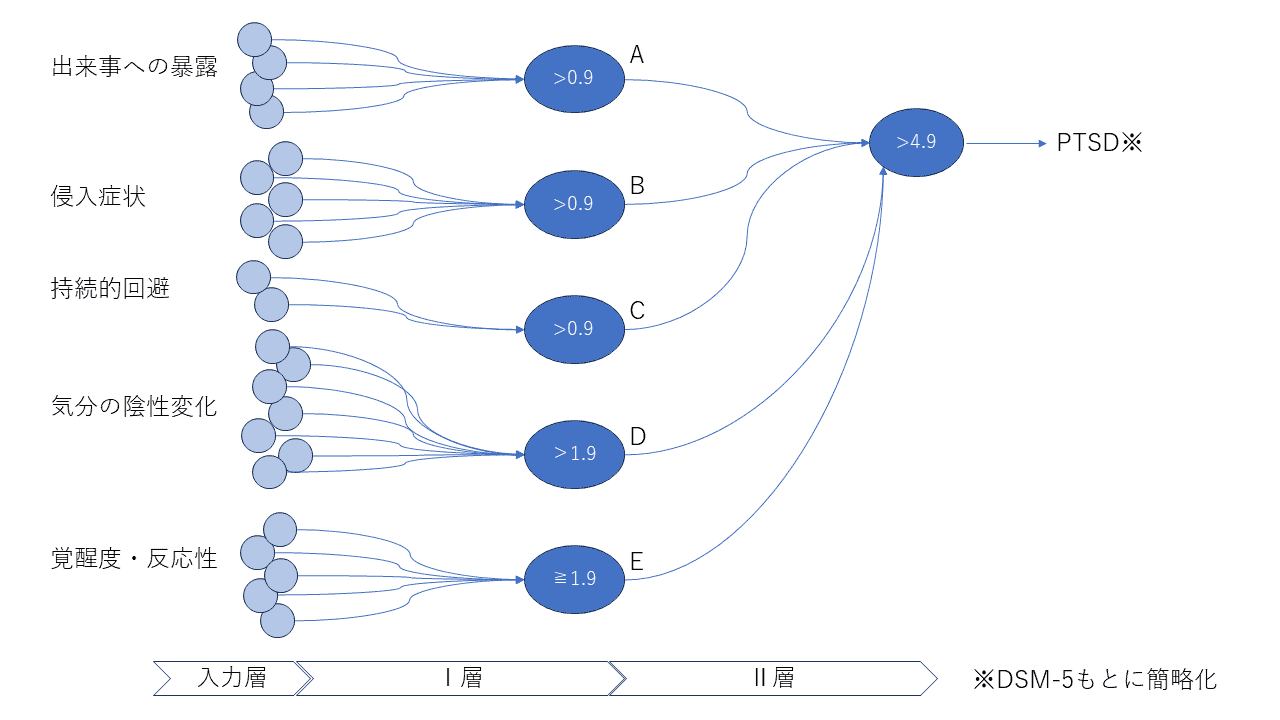
一番右の出力ニューロンは、A~Eのニューロン全てが反応しているときのみ反応します。
1+1+1+1+1>4.9
一つでも足りないと反応しません。つまりA~Eに該当する基準全てを満たすことがPTSDの条件になっています。
「侵入症状」は5つの症状が挙げられていて、その1つ以上が該当すれば、ニューロンBが反応して1を出力します。
0+0+0+1+0>0.9
「気分の陰性変化」は7つの症状が挙げられていて、そのうち2つ以上が該当すれば、ニューロンDが反応して1を出力します。
0+0+1+0+0+1+0>1.9
じわじわと診断基準がニューラルネットワークに見えてきましたか?
知識を計算できるようにする
数式で表すことができれば、ニューロンを模した機械部品を実際につくらなくても、コンピューターにシミュレーションさせることができます。
上記のPTSD診断のⅠ層とⅡ層は、重みパラメータWⅠ、WⅡで表現することができます。
上記のニューラルネットワークの図とどのように対応しているか比べてみてください。ニューラルネットワークをコンピュータ向けに翻訳したものがこれらの行列です。
\[\scriptsize{\eqalign{W^Ⅰ &= \begin{pmatrix} -0.9 & 1 & 1 & 1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \cr -0.9 & 0 & 0 & 0 & 0 & 1 & 1 & 1 & 1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \cr -0.9 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \cr -1.9 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 0 & 0 & 0 & 0 & 0 \cr -1.9 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 1 & 1 & 1 & 1 \cr \end{pmatrix} \cr W^Ⅱ &= \begin{pmatrix}-4.9&1&1&1&1 &1 \cr\end{pmatrix}}}\]これがAIの知識(この場合は診断基準)を表します。この程度の知識量なら人間が書き下ろすことが可能ですが、実際のAIではこの何億倍もの複雑な知識を扱うことが可能です。
ニューラルネットワークの数理
線形代数を読める方はもう少し数式を見てみましょう。そうでない方は読み飛ばして次の節へ。
PTSD診断のモデルは、数式で表すと次のようになります。
\[\eqalign{Ⅰ層の出力 &= Step(W^Ⅰ ×trick(入力層の出力)) \crⅡ層の出力 &= Step(W^Ⅱ ×trick(Ⅰ層の出力)) \cr}\]※trick()は閾値を扱うための小細工の関数です。
\[trick(\begin{pmatrix}x_1 \cr x_2 \cr x_3 \cr \vdots x_n\end{pmatrix}) = \begin{pmatrix}1 \cr x_1 \cr x_2 \cr x_3 \cr \vdots x_n\end{pmatrix}\]※Step()は行列用のステップ関数です。
\[Step(\begin{pmatrix}x_1 \cr x_2 \cr x_3 \cr \vdots x_n\end{pmatrix}) = \begin{pmatrix}step(x_1) \cr step(x_2) \cr step(x_3) \cr \vdots step(x_n)\end{pmatrix}\]Kojunによる数式の解釈
足し合わせるってこと(Σ)と、0か1に振り分ける(step())を交互に繰り返す構造になっています。
間接民主制みたいですね。
「合わす」と「分ける」の繰り返し。みんなの意見を聞くのが「合わす」。「あえてどっちかに決める」みたいなのが「分ける」。
これは、ブレストと意思決定を繰り返したり、発散思考と収束思考を繰り返す、オープンさとリーダーシップ、恋愛と結婚にも似ていますね。
合わすと分けるの重ね合わせで知能というものが出来るのだと思います。
ちなみに、理解できるという意味の「分かる」は「分けることが出来る」が語源だそうです。
診断マニュアルも、複数の症状を考慮する「合わす」っぽさと、あえて決めつけちゃう「分ける」っぽさを持っているように思います。「診」と「断」ですね。ですから、これもニューラルネットワークで表現できちゃうのでしょう。
医療ではない心理セラピストの私たちは「見立てる」と言いますが、「見る」と「立てる」ですね。
多層になれば、ステップ関数のおかげで、単なる巨大な多数決にならずに済みます。
そして、出力が次の層の複数のニューロンに配られることで、並列に多様な視点での判断ができます。こちらは「別れる」ですね。
それをまた「合わす」おかげで「分ける」(どっちかに振り分けて決めつける)だけよりは柔軟になれるのかもしれません。
これを「滑らかでない世界」への適応力として捉えることもできるようです。
(前略)この結果により、潜在的に滑らかでない構造を持つデータを解析する場合は、深層学習が相対的に優れた精度を発揮しうることが数学的に示された。例えば前述の相転移現象(引用者注:氷から水へ、水から蒸気へなどの変化)から生成されたデータを解析する場合、多くの層を持つニューラルネットワークが他手法より優れていることが数学的に保証される。
今泉允聡『深層学習の原理に迫る』p.42
自然界の滑らかな変化と急激な変化を多層のネットワークが捉えることができるというのが数学的に示されているということであれば、自然界を捉えたり、行動を調整したいりする知能のを原理的に理解するのに役立つ可能性は高いように思います。
人間用マニュアルとAIモデルの違い
もともとDSM-5は操作的診断基準(手順通りにやれば診断できるプログラムのようなもの)なので、「DSM-5に基づいて診断結果を表示する」ということだけのシステム(診断支援システム?)は、暇さえあれば数年前の中級プログラマーでも作れたでしょう。それだけなら、ニューラルネットワークである必要すらありません。
それと何が異なるのでしょうか?
機械学習ができる
一つは、AIが学習して重みWⅠ、WⅡを発見してゆくことができるということです。
たとえば、最初にデタラメなWⅠ、WⅡを用意して、100件の症例データ(症状と診断のセット)で正解率を測定します。WⅠ、WⅡに小さな変更を加えてみて正解率が上がるか下がるか測定します。正解率が上がればその変更を取り入れて、下がれば変更前に戻します。これを他のデータも使って10000回繰り返すとある程度まで正解率が上がってゆくことが想像でできるでしょう。実際の機械学習はもっと効率的な方法ですが。
つまり膨大な症例データがあれば、人間ではなくAIが診断基準を調整する可能性があるってことですね。(ただし、この場合は答え合わせデータは人間が提供している)
この「AIの学習」という概念にはAIが診断基準(のようなもの)を作るということも含まれます。
診断名、「症状を定義すること」「障害の分類を作ること」は上記のモデルのWⅠ、WⅡを発見することほど簡単ではないでしょうから、ただちにAIが診断基準を作れるとは言いません。しかし、それも原理的には可能になってきたということです。それが昔のエキスパートシステムとの決定的な違いです。
診断基準の調整ということで言えば、上記モデルは重みが0か1かですが、0.4とか0.8のような強弱をつけることも可能です。
複雑な知識を扱える
上記のうつ病診断モデルは3層、PTSD診断モデルは2層ですが、WⅠ、WⅡ、WⅢ、WⅣ、・・・と多層にすることで、「ただし、イノシシ症状とシカ症状とチョウ症状が同時にあれば、他の条件は不問」みたいな複雑な追加ロジックをたくさん盛り込むこともできます。
複雑にしすぎると不正確になるという現象もあるので、必ずしも複雑であるほどよいわけではありません。しかし、ニューロンの数はかなり増やせます。つまり、これは性能の話ではなくて、キャパの話です。
昨今のAIは数十もの層を持ちます。各層はニューロンとパラメータを含みます。
| ニューラルネットワーク | ニューロン数 | シナプス数 (パラメータ数) |
|---|---|---|
| 上記のPTSD診断モデル | 29 | (15×5+5×1=)120 |
| 上記のウツ診断モデル | 28 | (16×9+9×2+2×1=)164 |
| 線虫(C.エレガンス) | 300 | ~7500 |
| DSM-5診断基準全体 | 1万 | 推定10万~100万 |
| ヒル | 1万 | – |
| ChatGPT3 | – | 1750億 |
| ハツカネズミ | 8億 | 1兆 |
| 人間の脳 | 1000億 | 1000兆 |
シナプスとはニューロンの出力部(軸索の枝分かれした先)が、別のニューロンの入力部に接続する箇所のことです。モデル図の曲線矢印の本数がシナプス数(パラーメータ数)です。
DSM-5に書かれているのは400疾患くらいだそうなので、上記モデルの400倍すると約6万パラメータ。もう少し多く見積もって、ざっくりDSM-5診断基準(面接技術、観察技術などは含まない)のパラメータ数は10万~100万くらいでしょうか。
※なお、同じ機能であればパラメータが少ないほうが、開発者としては良い仕事をしたことになります。
診断基準は名医を再現しているというよりは、人間でも運用できるように”あえて”シンプルにしてあるのだというよにも見えます。
AIでは「人間でも運用できる」という制約がないために、キャパに大きな余裕があります。「マニュアルによる操作的診断の百倍、千倍もの何かが可能」というのがAIによる診断/アセスメントです。
しかし、そもそも「診断」が人工的なもの(正解を教えるのは人間。教師有学習)であるかぎり、キャパを大きくしても意味はないかもしれませんが。
臨床を振り返る示唆
この記事で挙げたのはかなり単純化したモデルですが、それでも診断基準がなんなのかということについて理解が深まります。
診断基準で全てを捉えきれないのは当たり前
人間用の診断マニュアルがあえてシンプルンに(ニューラルネットワークで言うと「浅く」)作られているのだとすると、「DSM-5のような診断基準では全てを捉えることができない」という批判に対しては、「そりゃそうでしょ、あえてそうしているんだから」という理解ができます。
診断基準で全てを捉えることができないのは、その完成度の問題ではなくて、人間の能力に配慮して浅くしておく都合もあるのでしょう。
DSM-5の冒頭にもその限界については書かれています。
*生身の人間でも扱えるように、パラメータ数を小規模に抑えているために、診断基準は疾患ごとに独立にシンプルに作られています。
ということは、複数の障害が並存したり、複数の要因が単純な足し合わせでなく絡む場合に診断マニュアルは無力になる(専門家の直感のほうがマシになる)可能性を示唆しているかもせれません。
しかし、人間用ではなく、AI用の診断モデルとなるとパラメータ数の遠慮は要らなくなるので、多要因も扱える可能性があります。ただし人間には理解できない診断名になる可能性はありますが。「XR02系448疾患」みたいな。
診断マニュアルは浅くて広い知識
上述のように人間がマニュアルとして使う都合もあり、シンプルです。これは、「ニューラルネットの層が浅い」と言い換えることができます。
ですから、診断マニュアルは患者を深く理解するためのものではないということになります。
様々な疾患に視野を広げてその中から大まか捉えるためのものということが理解できそうです。
これを別の言葉で大胆に表現するなら、診断マニュアルは「患者が〇〇疾患であることが判る」ためのものというよりは「患者が他の疾患ではないことが判る」ためのもの(鑑別?)、と言えるかもしれません。
となると、臨床家は得意分野ではない疾患の診断基準こそ見ておく価値がありそうです。
臨床家の暗黙知
「診断基準は満たさないけど、PTSDと同じようにケアしたほうがよいように思います」みたいな判断などですね。
あるいは、臨床家は「侵入症状が強い場合は、CPT療法よりもPE療法の方が合っているように思う」というような判断もします。これをモデルにしてみましょう。
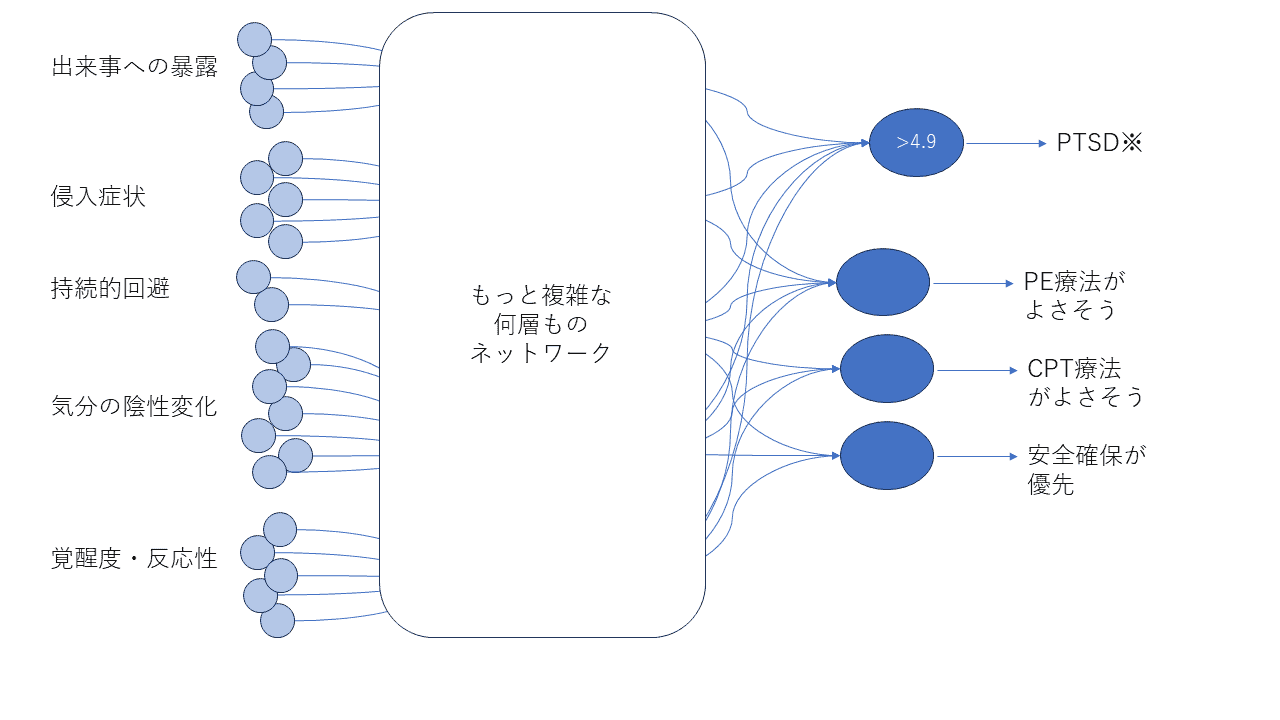
「おい、なんで肝心なところを隠すの!」
すみません。その中間層がなんだか分からなくてもモデルが作れちゃうっていうのが、機械学習の特徴なんです。この中間層は「隠れ層」と呼ばれたりするくらいですから。
人間にも「ロジカルに説明するのは難しいですが・・・」みたいな暗黙知がありますね。
診断基準とはまた別の暗黙知を持っている臨床家もいるでしょう。
無難なスタンスとしては、どのような症状に注目するか(上記モデルの入力層に相当)は診断基準をベースにして、対応判断(モデルの出力側)を経験によって拡張しているという臨床家が多いかもしれません。
隠れ層なくして知能が実現できない様から、暗黙知=形式知に劣るものではないということが見えてきます。
臨床心理学では暗黙知を排除することが科学であるかのような主張がされますが、むしろ科学は暗黙知を支持しています。
専門性が唯一の知能ではない
上述の「分ける」と「別れる」は知能の二つの方向性と捉えることができると思います。分けるというのは、一つの基準によって決めつけることなので、一つの理論や学派に固執することに似ています。専門家というのは「分かる」ことが得意なのかもしれません。
一方で「別れる」は、心理実践では複眼と呼ばれるものに近いです。複数のアプローチからの意見を統合することはAI業界ではアンサンブルと呼ばれています。
「分かる」という専門性だけでなく、「別れる」(他の解釈を併存させる)という複眼を持たない臨床は、AIに越されてゆくよという示唆にも思えます。
ファジーさがないと学べない
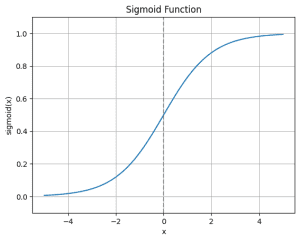
上に挙げた診断モデルの重みはすべて0か1でしたが、ニューラルネットワークが学習を行うためには、0.4や2.7などの連続値な重みを扱える必要があります。ステップ関数もシグモイド関数(曲線ぽいステップ関数みたいなの)等に置き替える必要があります。(スケーリングは別途調整)
これは、知識をちょっと変化させることで結果がどう変わるかを試行錯誤することができなければ学習は難しいということを示唆しているように思います。
「発達障害か、発達障害でないか」「〇〇療法は効果があるか、効果がないか」「〇〇理論は正しいか、正しくないか」という二値な世界観では新しいことを学べないという示唆でしょうか。
適度にスペクトラムとして捉える臨床家はそうでない場合に比べて、同じ件数の症例でも数十倍の速さで学ぶのかもしれません。
研究者が優秀なら専門職の専門性は下がるはず
診断モデルが大きい(パラメータ数が多い)ということは、マニュアルを使って診断する人が優秀である必要性を意味しますが、モデルの開発者が優秀であることを意味しません。
モデルが小さいということは、開発者が優秀であることを意味し、マニュアルを使う人に要求される専門性は低くなります。
臨床心理学者が専門家として優秀であれば、臨床技術の敷居が下がり(もしくは自動化され)、臨床家は逆にゼネラリスト化されるはずということが示唆されるようにも思います。(自動車技術が発達してオートマが発明されると運転者の裾野は広がります)
「心理支援の技術が日進月歩で高度化している。どんどん学ぶことが増えて心理職の専門性が高まる」と捉える意見がありますが、それが本当なら心理支援の研究はまだまだ黎明期、科学技術と呼ぶには程遠いということかと思います。「以前は10年間かけて学んでいた技術が、今日では半年で使いこなせるようになった」となるのが科学技術の進歩。それくらいのインパクトがなければ、高度な技術とは言わないように思います。
もし臨床心理学が科学技術的であればなお、「専門カリキュラムの大学院までいかないと心理カウンセリング出来ない」というのは、臨床心理学の研究者や学術界にとって自慢できる話ではなくなるように思います。
アセスメントは循環している
このニューラルネットワークの入力項目(注目すべき症状)と、出力カテゴリ(診断名)はどのように決まるのでしょうか?
シナプス結合を機械学習により作ろうとするなら、診断名はクラスター分析のような教師無し機械学習(のようなこと)をすることになるでしょう。そのためには症状群が決まっている必要があります。
一方で、入力となる症状群を決めること(特徴量抽出といいます)は、診断名という出力が先に定義されていている必要があります。目的がないと社会通念に合わないものが症状とされてしまいます。(マイノリティであることが症状として扱われる)
このことは、機械学習ではなく、権威者の意見によって診断マニュアルをつくる場合にも見え隠れするジレンマです。さらに、これは診断マニュアルに限ったことではなく、臨床心理の見立てて全般に関することです。
症状群からカテゴライズで診断名を決めておきながら、診断名ありきで症状群を抽出するという循環的な説明になります。
「フラッシュバック(PTSDの症状の一つ)が起きるのは悪魔が取り憑いているからでした」と納得する一方で、悪魔が取り憑いているという判断規準を「フラッシュバックが頻繁に起きる」とする。このようなものをトートーロジー的とか、循環論法と言います。これらは論理的に真として扱えますが、科学的な知識ではありません。それと同じになってないかということです。
心理のアセスメントは、わりとそうなりがちです。
データサエンティストがこの循環に気づくのは一日もかからないでしょう。
「循環理論なのはしょうがない。それは科学ではなく一つのイデオロギーとして記述しましょ」となるのか、数式や関係図で接地が説明される日がくるのか。厳密に定義されただけでは(客観的であるだけでは)科学ではないということですね。
アセスメントの未来の可能性
より細やかな「意見」も出せる
もしAIが人間用の診断基準よりもっと細やかな情報を扱えるのであれば、もしもAIが診断補助するようになったら、DSM-5による操作的判定に加えて、「ディープラーニングによる意見」も出力されることが想像されます。
「障害Aと障害Bの診断基準を全部ではないが部分的に満たす」とか、「うつ病の全ての症状が少しだけある」とかの場合に、何らかの判断をすることができるかもしれません。
これは上述の臨床家の暗黙知にも似ているように思います。
普遍性から個別性へ
療法や対処法を選ぶ判断ということになると、セラピストが何が得意かということにも関係してきます。
たとえば「持続的回避」が非常に強い場合、「真正面から体験に向き合うPE療法は難しい」と判断するセラピストもいるでしょう。しかし、「だからこそプログラムかっちりのPE療法でやるのがよい」というセラピストもいるでしょう。そこにはセラピストの得意不得意や持ち味も関係しています。
印刷された診断マニュアルや統計目的の診断では、世界中が同じ基準を使う必要がありますが、「個別のディープラーニングによる意見」であればそのセラピストやそのチームごとに異なるモデルを育てることも可能です。
もしかしたら、なにが正解であるかを論争するなんてことは時代遅れになるかもしれません。
インタラクティブ性
診断基準は一方的で、患者や相談者は情報の下流の末端に位置します。しかし、AIならインタラクティブなアセスメントが可能です。患者や相談者が「そうじゃなくて・・・」と言えば、枠組みを変えてくれることもできます。専門知識に人を合わせるのではなく、人に専門知識を合わせるという世界も実現可能です。
権威者たちがそれを許すかどうかはわかりませんが、専門知識の民主化ということが起きる可能性があります。
暗黙知の捉え方が変わる
心理学業界では「暗黙知を排除することが科学である」かのような風潮があります。しかし、お隣の業界では科学や数学が暗黙知を証明してしまうことが起きているようです。
暗黙知が存在することが、科学的に認識されるようになるかもしれません。
AIが見つけ出す特徴量とか、隠れ層のネットワークは、臨床家の暗黙知に相当するように思います。
暗黙知は言葉で説明できないものを多く含みます。「共感」とか「力動」みたいに、用語はあるものの、客観的に測定できないものもあります。
たとえば「症状」は特徴量の一種ですが、人間の言葉では表せない特徴量でもAIにとっては「症状」です。
〇〇症の共通因子「100101100011」症状みたいな自然言語が対応しないものを人間が理解して扱うことは困難ですが、AIならそのような因子を100個使って判断することもできます。
症状の引き算や足し算が計算できるように症状の体系を自動的に作ることもできそうです。
※症状の引き算とは「ウツだけど大ウツぽくはない」とか「トラウマを体験しているけど、出来事が明確ではない」とかでしょうか。
人間には理解できない特徴量のことは、「潜在的な意味」などと呼ばれ、AIが高度化するために必須の要素になっています。
近い将来に「臨床家の暗黙知は存在する」とか「暗黙知の大きさを比較する」ということが研究される可能性はあるのではないでしょうか。
入力層の進化
このモデルでは入力として扱われている症状群は、特徴量と呼ばれます。
しかし、何をもって「持続的回避」症状とするか、というような判断にも実は知能は必要です。
上に挙げたモデルの入力層より左側には、問診とか尺度検査とか観察が存在するでしょう。
もしクライアントや患者の言葉や行動履歴などのデータが蓄積されると、AIが特徴量を発見してゆくことになるかもしれません。
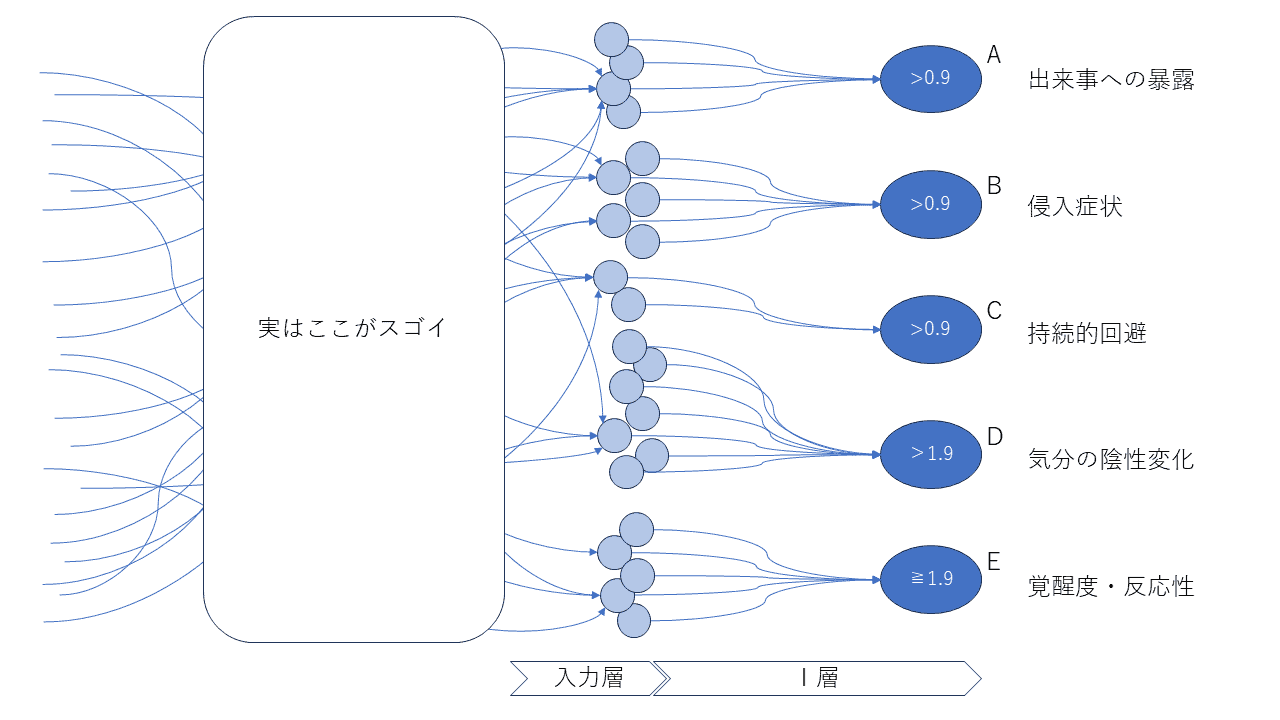
実は昨今の第3次AIブームを引き起こしている「ディープラーニング」というのは「多層」という意味ですが、その「多層」を別の表現にすると「AIが自分で特徴量を見つけちゃう」という意味だったりもします。
もしAIが診断をするようになったら、診断マニュアルがあえて省略している部分、上述の「入力層の左側」に膨大な暗黙知を築く余力がありそうです。
患者の表情や音声や生活データを入力とする診断システムが研究されているそうです。レントゲン画像認識AIみたいな感じですね。
出力層の進化
これは重要なことで、最後にこっそり書くことではないかもしれませんが・・・。
診断が目的ではなくなるかもってことです。治療方針を出すことが目的であって、診断は中間層の特徴ベクトルに過ぎない、もしくは説明性の一要素にすぎないということ。
そうなると、医学的な治療だけサジェストされるようにシステムに縛りをかけるのかどうか、社会的、政治的な問題が浮かび上がります。
参考
- AIってなに? ①AIの「本質」とは |たてはま / CGBeginner – Youtube
- ニューラルネットワークの仕組み | Chapter 1, 深層学習(ディープラーニング)3Blue1BrownJapan – Youtube
- 【神経系】シナプス伝達(EPSPとIPSP) | ゴロー/イラストで学ぶ体の仕組み – Youtube
- 「脳科学と心理療法」岡野憲一郎 | オンライン・マガジン「シンリンラボ」
- 『DSM-5 精神疾患の分類と診断の手引』米国精神医学会
- 精神医学における類型と疾患単位―「実在するもの」と「そのように呼ぶもの」 | メディカルノート
- 『超解読! はじめてのフッサール『イデーン』』まえがき,序論 竹田 青嗣, 荒井 訓(Audible)
- 『計算論的精神医学』国里愛彦、片平健太郎、沖村宰、山下祐一
- 『深層学習の原理に迫る』今泉允聡
- 『統計学が最強の学問である[数学編]』西内啓
- 『脳科学が精神分析と出会ったら?』加藤隆弘
- 『小林秀雄講演: 本居宣長』(オーディオブック)
